
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 생성자 new
- new 사용법
- Index Range Scan
- 이중 연결 리스트
- javascript 생성자
- javascript this
- 큐 연결리스트
- javascript prototype
- javascript new
- 스택
- npm Option
- 포인터
- 확장 엘리먼트
- 배열
- 연결 리스트
- 연결리스트
- access
- 스택 배열
- Loose Index Scan
- 추상적 자료 구조
- c언어 스택 배열
- pattern
- Index Skip Scan
- jQuery
- 생성자
- 연동
- Index Full Scan
- C#
- 배열 스택
- 자료구조
- Today
- Total
목록분류 전체보기 (55)
Open-Closed Principle
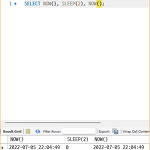 MySQL 현재 시각 조회(NOW, SYSDATE)
MySQL 현재 시각 조회(NOW, SYSDATE)
두 함수 모두 현재의 시간을 반환하는 함수로서 같은 기능을 수행한다. 하지만 NOW()와 SYSDATE() 함수는 작동 방식에서 큰 차이가 있다. 하나의 SQL에서 모든 NOW() 함수는 같은 값을 가지지만 SYSDATE() 함수는 하나의 SQL 내에서 호출되는 시점에 따라 결괏값이 달라진다. CASE 1. NOW() CASE 2. SYSDATE() NOW() 함수를 사용한 첫 번째 예제에서는 두 번의 NOW() 함수 결과가 같은 값을 반환했다. 하지만 두 번째 예제에서 사용된 SYSDATE() 함수는 SLEEP() 함수의 대기 시간인 2초 동안의 차이가 있음을 알 수 있다. SYSDATE() 함수는 이러한 특성 탓에 두 가지 큰 잠재적인 문제가 있다. 첫 번째로는 SYSDATE() 함수가 사용된 SQL..
1. MySQL 사용자 계정 추가 (인증플러그인) 2. MYSQL 사용자 계정 추가 (비밀번호관리/잠금) 기본 예 1 2 3 4 5 6 7 8 9 CREATE USER 'user'@'%' IDENTIFIED WITH 'mysql_native_password' BY 'password' REQUIRE NONE PASSWORD EXPIRE INTERVAL 30 DAY ACCOUNT UNLOCK PASSWORD HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFUALT PASSWORD REQUIRE CURRENT DEFUALT; cs 3. PASSWORD EXPIRE 비밀번호의 유효 기간을 서정하는 옵션이며, 별도로 명시하지 않으면 default_password_lifetime 시스템..
1. MySQL 사용자 계정 추가 (인증플러그인) 2. MYSQL 사용자 계정 추가 (비밀번호관리/잠금) 기본 예 1 2 3 4 5 6 7 8 CREATE USER 'user'@'%' IDENTIFIED WITH 'mysql_native_password' BY 'password' REQUIRE NONE PASSWORD EXPIRE INTERVAL 30 DAY ACCOUNT UNLOCK PASSWORD HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFUALT PASSWORD REQUIRE CURRENT DEFUALT; cs 1. IDENTIFIED WITH (인증플러그인) MySQL 서버의 기본 인증 방식을 사용하고자 한다면 IDENTIFIED BY 'password' 형식으로..
Index Range Scan 인덱스에서 조건을 만족하는 값이 저장된 위치를 찾는다. 이 과정을 인덱스 탐색(Index Seek)이라고 한다. 탐색된 위치부터 필요한 만큼 인덱스를 차례대로 쭉 읽는다. 이 과정을 인덱스 스캔(Index Scan)이라고 한다 읽어 들인 인덱스 키와 레코드 주소를 이용해 레코드가 저장된 페이지를 가져오고, 최종 레코드를 읽어온다. Index Full Scan 인덱스의 처음부터 끝까지 모두 읽는 방식을 인덱스 풀 스캔이라고 한다. 대표적으로 쿼리의 조건절에 사용된 컬럼이 인덱스의 첫 번째 카럼이 아닌 경우 인덱스 풀 스캔 방식이 사용된다. 인덱스의 크기는 테이블의 크기보다 작으므로 직접 테이블을 처음부터 끝까지 읽는 것보다는 인덱스만 읽는 것이 효율적이다. 인덱스뿐만 아니라 ..
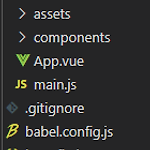 Vue 프로젝트 파일
Vue 프로젝트 파일
- node_modules : npm으로 설치된 패키지 파일들이 모여 있는 디렉토리 - public : 웹팩(webpack)을 통해 관리되지 않는 정적 리소스가 모여 있는 디렉토리 - src/assets : 이미지, css, 폰트 등을 관리하는 디렉토리 - App.vue : 최상위(Root) 컴포넌트 - main.js : 가장 먼저 실행되는 자바스크립트 파일로써, Vue 인스턴스를 생성하는 역할 - .gitignore : 깃허브에 업로드 할 때 제외할 파일 설정 - babel.config.js : 바벨(Babel) 설정 파일 - package.json : 프로젝트에 필요할 package를 정의하고 관리하는 파일 - package-lock.json : 설치된 package의 dependency 정보를 관리..
실무에서 프로젝트를 계속 개발하다 보면 설치된 패키지가 많아진다. 만약 다른 팀원들과 공동 작업을 하고 있다면 매번 패키지 파일 전체를 공유 하는 것은 말이 안되다. 그래서 패키지를 설치할 때 --save 옵션을 사용한다. --save 옵션을 사용하면 package.json파일에 설치한 패키지 정보가 추가 된다. 그래서 package.json만 공유하여 npm install 만 하면 서로 공유 하는 것과 동일한 효과를 볼 수 있다. Git으로 소스를 관리할 때도 유용하다. 끝
컬럼 수정 EXEC sp_updateextendedproperty @name = N'MS_Description', @value = '내용 입력', @level0type = N'Schema', @level0name = dbo, @level1type = N'Table', @level1name = '테이블명', @level2type = N'Column', @level2name = '컬럼명'; 테이블 수정 EXEC sp_updateextendedproperty @name = N'MS_Description', @value = '내용', @level0type = N'Schema', @level0name = dbo, @level1type = N'Table', @level1name = '테이블명';
연결 리스트로 큐를 구현하면 동적 할당의 성질에 의해 메모리의 한계까지 큐의 크기를 늘릴 수도 있고, 또 큐가 아주 작을 때에도 메모리도 조금 밖에 차지하지 않는다. 단순 연결 리스트를 이용하여 큐를 구현하는 것은 약간의 무리가 있다. 큐를 구현하려면 앞 노드의 위치와 뒷 노드의 위치를 모두 알고 있어야 하므로 할 수 없이 이중 경결 리스트를 사용하여야 한다. 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101..
큐는 입구와 출구가 따로 있는 긴 통이라고 생각하면 된다. 큐는 접근이 제한된 자료구조이며 행위적 측면을 부여받은 추상적 자료형이기 때문에 큐를 조작하는 방법은 두가지로 제한되어 있다. 큐를 조작하는 방법은 put 동작과 get 동작이 있다. 큐에 자료를 집어넣을 때는 뒤(rear)에서 집어넣는다. 이 집어넣는 동작은 put 동작이라고 한다. 그리고 큐에서 자료를 얻어낼 때는 앞(front)에서 얻어낸다. 이 자료를 얻는 동작은 get 동작이라고 한다. 배열을 이용해서 큐를 구현하는 것은 문제가 없어 보이지만 문제가 많다. 배열을 이용한 큐의 구현은 자료를 저장할 배열과 앞과 뒤를 가리키는 변수만 있으면 될 것같다. 하지만 큐에 자료를 집어 넣고 빼는 동작을 계속하다보면 rear와 front는 계속 증가..
연결리스트 자체가 동적인 할당을 통해서 구현되기 때문에 연결리스트를 이용해서 구현되는 스탹은 매우 유연하다. 연결 리스트를 이용하여 스택을 구현할 때의 장점은 현재 스택에 저장되어 있는 자료 만큼만 메모리를 잡아먹기 때문에 메모리가 절약되고 스택의 크기가 메모리가 허용하는 한도에서 커질 수 있다는 것이다. 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788#include #include // 리스트 노드 typedef struct _node{ int key; ..