
1. DISTINCT의 정의
DISTINCT는 MySQL에서 사용되는 키워드로, 중복된 데이터를 제거하여 유일한 값만을 반환할 때 사용됩니다. 데이터베이스 쿼리에서 여러 조건에 의해 같은 값이 반복적으로 나타날 수 있으며, 이러한 중복 값을 제거하고자 할 때 DISTINCT 키워드를 사용하면 됩니다.
특정 컬럼의 데이터가 여러 번 반복되어 나타나는 경우도 있지만, 사용자가 중복을 원하지 않는 상황이 있을 수 있습니다. 예를 들어, 여러 고객의 주문 기록을 조회할 때, 각 고객의 ID만을 중복 없이 출력하고 싶다면 DISTINCT를 활용할 수 있습니다.
DISTINCT의 기본 문법
SELECT DISTINCT column1, column2, ...
FROM table_name;위의 문법에서 column1, column2, ...는 중복을 제거하고자 하는 컬럼을 의미하며, 테이블에서 해당 컬럼들의 중복을 제외한 고유한 값만을 반환합니다.
2. DISTINCT의 사용법 및 예시
우선 테스트에 사용하기 위한 기본 테이블을 아래와 같이 생성합니다.
- 고객 테이블
CREATE TABLE customers (
customer_id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
country VARCHAR(50)
);- 주문 테이블
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
customer_id INT,
order_date DATE,
amount DECIMAL(10, 2),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);- 고객 데이터
INSERT INTO customers (first_name, last_name, country)
VALUES
('John', 'Doe', 'USA'),
('Jane', 'Doe', 'USA'),
('John', 'Smith', 'Canada'),
('Mary', 'Johnson', 'USA'),
('Peter', 'Parker', 'Japan'),
('Bruce', 'Wayne', 'Korea'),
('Clark', 'Kent', 'Korea'),
('Diana', 'Prince', 'France');- 주문 데이터
INSERT INTO orders (customer_id, order_date, amount)
VALUES
(1, '2024-01-15', 100.50),
(2, '2024-01-20', 150.75),
(1, '2024-02-15', 200.00),
(3, '2024-03-10', 75.25),
(4, '2024-04-05', 300.00),
(2, '2024-05-12', 50.00),
(5, '2024-06-15', 400.00),
(6, '2024-07-20', 500.00),
(7, '2024-08-01', 600.00),
(8, '2024-09-10', 700.00);2.1. 단일 컬럼에 DISTINCT 사용
하나의 컬럼에서 중복된 데이터를 제거하고자 할 때는 아래와 같이 DISTINCT를 사용합니다.
- 예시
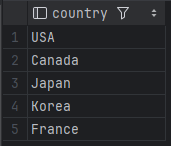
SELECT DISTINCT country
FROM customers;이 쿼리는 customers 테이블에서 country 컬럼에 있는 고유한 국가들만 출력합니다. 만약 customers 테이블에 100개의 고객 정보가 있고, 이 중 20명이 한국에 있다면 결과에는 '한국'이 한 번만 나타나게 됩니다.
- 결과
2.2. 여러 컬럼에 DISTINCT 사용
여러 컬럼에 대해 중복을 제거하고 싶다면, DISTINCT를 여러 컬럼에 적용할 수 있습니다. 이때 DISTINCT는 지정된 모든 컬럼의 조합이 동일한 경우 중복을 제거합니다.
- 예시
SELECT DISTINCT first_name, last_name
FROM customers;이 쿼리는 employees 테이블에서 직원들의 이름과 성이 모두 같은 경우에만 중복을 제거하여 출력합니다. 즉, first_name과 last_name이 모두 동일한 행만 중복을 제거하여 보여줍니다.
- 결과

2.3. COUNT와 함께 DISTINCT 사용
종종 특정 컬럼에서 중복된 값을 제거한 후, 그 결과에 대한 개수를 알고 싶을 때가 있습니다. 이 경우 COUNT 함수와 DISTINCT를 함께 사용할 수 있습니다.
- 예시
SELECT country, COUNT(DISTINCT customer_id) AS num_customers
FROM customers
GROUP BY country;이 쿼리는 customers 테이블에서 고유한 국가의 개수를 반환합니다. 중복된 국가들은 제거된 후 고유한 값들만 세어집니다.
- 결과

2.4. DISTINCT와 ORDER BY 함께 사용
DISTINCT와 ORDER BY는 함께 사용할 수 있습니다. 이 경우 먼저 DISTINCT로 중복을 제거한 후, 그 결과를 ORDER BY로 정렬합니다.
- 예시
SELECT DISTINCT country
FROM customers
ORDER BY country ASC;이 쿼리는 customers 테이블에서 중복된 국가를 제거한 후, 알파벳 순으로 오름차순으로 정렬하여 출력합니다.
- 결과

3. DISTINCT와 GROUP BY의 차이
DISTINCT와 GROUP BY는 모두 중복을 처리할 수 있지만, 그 사용 목적과 동작 방식이 다릅니다.
DISTINCT: 단순히 중복된 행을 제거하고 유일한 값을 반환합니다.GROUP BY: 데이터를 그룹화하고, 각 그룹에 대한 집계 함수(예:COUNT,SUM)를 적용할 때 주로 사용됩니다.
예시로 비교하기
DISTINCT:
SELECT DISTINCT country
FROM customers;이 쿼리는 customers 테이블에서 중복된 국가를 제거하고, 고유한 국가 리스트를 출력합니다.
GROUP BY:
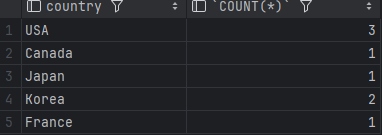
SELECT country, COUNT(*)
FROM customers
GROUP BY country;이 쿼리는 각 국가별로 고객의 수를 집계하여 출력합니다.
- 결과:
따라서 DISTINCT는 단순히 중복 제거용으로 사용되지만, GROUP BY는 데이터 집계에 더 적합합니다.
4. 성능 고려사항
대용량 데이터에서 DISTINCT를 사용하면 성능에 영향을 줄 수 있습니다. 특히 여러 컬럼에 DISTINCT를 적용할 경우, 데이터베이스는 중복을 제거하기 위해 많은 계산을 해야 합니다. 따라서 적절한 인덱스 설정이나 데이터 구조의 최적화가 필요합니다.
성능 최적화를 위한 팁
- 인덱스 사용:
DISTINCT를 사용하는 컬럼에 인덱스를 설정하면, 중복 제거를 보다 효율적으로 처리할 수 있습니다. - 필요 없는 컬럼 제외:
DISTINCT를 사용할 때는 꼭 필요한 컬럼만 선택하는 것이 좋습니다. 불필요한 컬럼이 많을수록 중복 제거에 더 많은 리소스가 소모됩니다. - 서브쿼리 활용: 성능을 높이기 위해 서브쿼리를 사용하여 먼저 중복을 제거한 후, 다른 처리를 하는 방식도 고려할 수 있습니다.
5. 실제 사용 예시: 고객 주문 중복 제거
예를 들어, 고객이 주문을 여러 번 했을 때, 고객의 고유한 ID만 중복 없이 조회하고 싶다면 다음과 같은 쿼리를 사용할 수 있습니다.
- 예시
SELECT DISTINCT customer_id
FROM orders;
- 결과
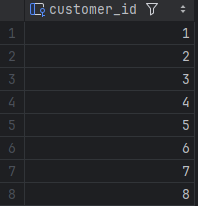
이 쿼리는 orders 테이블에서 중복된 고객 ID를 제거하고 고유한 고객 ID만 반환합니다.
또한, 특정 기간 동안 주문한 고객의 수를 알고 싶다면 다음과 같이 사용할 수 있습니다.
- 예시
SELECT COUNT(DISTINCT customer_id)
FROM orders
WHERE order_date BETWEEN '2024-01-01' AND '2024-01-31';
- 결과

이 쿼리는 2024년 01월 동안 주문한 고유한 고객의 수를 반환합니다.
6. 마무리
DISTINCT는 MySQL에서 중복 데이터를 제거하고 고유한 값을 조회하는 데 매우 유용한 도구입니다. 단일 컬럼부터 여러 컬럼에 걸쳐 중복을 제거할 수 있으며, 집계 함수나 정렬과도 함께 사용할 수 있습니다. 그러나 대량의 데이터에서 DISTINCT를 사용할 경우 성능에 영향을 미칠 수 있으므로, 적절한 인덱스 설정과 함께 최적화를 고려해야 합니다.
DISTINCT의 적절한 사용법을 숙지하고 다양한 쿼리에서 이를 활용함으로써, 효율적이고 깔끔한 데이터를 얻을 수 있습니다.
'DataBase' 카테고리의 다른 글
| MySQL 파티셔닝(Partitioning)의 기본 개념과 필요성 (0) | 2024.10.26 |
|---|---|
| MySQL GROUP BY에 대한 이해 (0) | 2024.10.24 |
| MySQL - EXISTS 함수 (0) | 2024.10.21 |
| MySQL - COUNT와 EXISTS 성능 비교 및 최적화 고민 (0) | 2024.10.21 |
| MySQL - COUNT 함수 (0) | 2024.10.21 |



