
Problem
SQL Server 전문가로 구성된 팀이 대량 삽입 문을 적용하여 파일 가져오기 프로젝트의 효율성을 개선하기를 원합니다. 대량 삽입 문에 대한 여러 사용 사례 예제를 제시해 주시면 저희가 실행해야 하는 파일 가져오기 프로젝트에 대량 삽입 문을 더 자주 적용하도록 동기를 부여할 수 있을 것 같습니다.
Solution
T-SQL 대량 삽입 문은 대용량 파일의 내용을 SQL Server 테이블에 입력하기 위해 특별히 설계되었습니다. 그러나 대량 삽입 문은 작은 파일뿐만 아니라 큰 파일 및/또는 여러 개의 중간 크기 파일을 가져오는 데에도 쉽게 적용할 수 있습니다. T-SQL로 프로그래밍하는 것을 좋아하거나 일부 파일 가져오기 프로젝트에서 SSIS가 과도하다고 판단되는 경우, 대량 삽입 문이 적절한 수준의 지원을 제공하고 성능상의 이점을 제공할 수 있습니다.
이 팁에서는 점진적으로 더 발전된 세 가지 대량 삽입 사용 사례에 대해 설명합니다. 다운로드에는 각 사용 사례 예제에 대한 샘플 데이터와 새로운 데이터로 연습할 수 있는 추가 데이터 샘플이 포함되어 있습니다.
- 사용 사례 #1: TXT 파일을 가져오기 위해 대량 삽입 문을 호출하고 가져온 파일에서 선택한 요소를 SQL Server 결과 집합으로 구문 분석하는 기본 사항을 설명합니다.
- 사용 사례 #2: 세 개의 파일을 각각 하나의 SQL Server 테이블로 가져오기 위한 T-SQL 코드를 작성하는 방법에 중점을 둡니다. 각 파일은 파일명을 사용하여 파일에 있는 데이터 유형에 대한 범주를 나타냅니다.
- 사용 사례 #3: SQL Server 대체 함수와 저장 프로시저를 통해 대량 삽입 문을 동적으로 만드는 방법과 이름으로 지정된 파일 집합을 SQL Server 테이블로 가져오는 방법을 설명합니다.
사용 사례 #1: TXT 파일을 SQL Server 결과 집합으로 가져오기
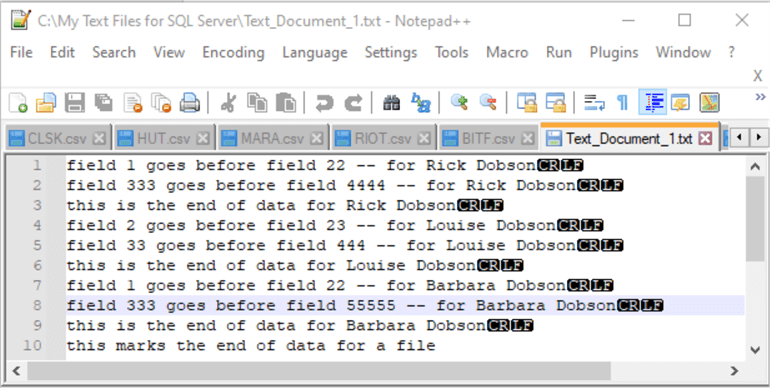
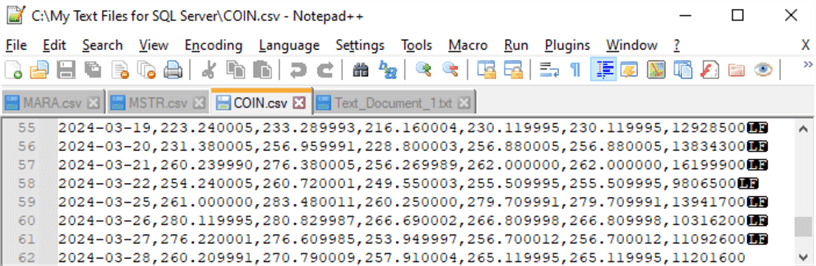
다음 스크린샷은 첫 번째 사용 사례 예시를 보여주기 위해 만든 임의의 TXT 파일의 내용을 보여줍니다. 이 파일은 메모장++ 세션에 나타납니다. 세션의 헤더를 보면 파일이 C 드라이브의 내 SQL Server용 텍스트 파일 폴더에 있음을 알 수 있습니다. 파일 이름은 Text_Document_1.txt입니다. 파일 이름과 파일 경로는 대량 삽입 문의 FROM 절에 필요하므로 중요합니다.
파일 내용은 Nodepad++ 세션 내에서 10줄로 표시됩니다. 처음 9줄의 끝에 있는 CR과 LF는 행 종결자입니다. 이러한 문자는 대량 삽입 문의 기본 행 종결자에 해당합니다. 파일의 마지막 줄에는 행 종결자가 필요하지 않습니다.
Text_Document_1.txt 파일의 Notepad++ 탭에 있는 데이터에는 자유 형식 텍스트, 즉 행과 열로 구분되거나 정리되지 않은 데이터가 들어 있습니다. 이 데이터는 Rick Dobson, Louise Dobson, Barbara Dobson이라는 세 사람에 대한 데이터입니다. 각 사람에 대한 데이터는 연속된 두 줄에 나타납니다. 각 사람에 대한 두 번째 줄 뒤에 세 번째 줄은 한 사람에 대한 데이터의 끝을 나타냅니다. 또 다른 줄 유형은 TXT 파일의 마지막 줄입니다. 이 줄은 파일의 끝을 표시합니다.
다음 스크립트는 첫 번째 사용 사례에 대한 T-SQL 코드를 보여줍니다.
- 스크립트 상단의 주석 블록에 있는 두 문은 for_char_data_lines 데이터베이스의 새 복사본을 생성합니다.
- 주석 블록 뒤의 다음 몇 줄은 for_char_data_lines 데이터베이스를 나머지 스크립트의 기본 데이터베이스로 지정하고 데이터베이스의 dbo 스키마에 char_data_lines 테이블의 새 복사본을 생성합니다.
- char_data_lines 테이블에 대한 테이블 생성 문 뒤에 있는 대량 삽입 문은 Text_Document_1.txt 파일의 행을 char_data_lines 테이블로 밀어 넣습니다.
- 대량 삽입 문 뒤의 코드는 char_data_lines 테이블의 행에서 세 개의 값 집합을 구문 분석합니다. 이러한 종류의 구문 분석 코드 버전은 일반적으로 자유 형식 텍스트 데이터를 가져오는 스크립트에 나타납니다.
/*
-- run once from a fresh SQL Server session
-- before invoking the uncommented code in this script
drop database if exists for_char_data_lines;
create database for_char_data_lines;
*/
-- create a fresh version of dbo.char_data_lines table -- in for_char_data_lines database
use for_char_data_lines;
drop table if exists char_data_lines;
create table dbo.char_data_lines (
line nvarchar(80)
);
-- bulk insert C:\My Text Files for SQL Server\Text_Document_1.txt
-- to the dbo.char_data_lines table
-- in the for_char_data_lines database
bulk insert dbo.char_data_lines
from 'C:\My Text Files for SQL Server\Text_Document_1.txt';
-- optionally display unparsed lines from dbo.char_data_lines tables
-- select * from dbo.char_data_lines
-- parse first and second field values
-- along with full name from each line
select line
,substring(
line
,charindex(' ',line)+1
,(charindex(' ',line,charindex(' ',line)+1)-charindex(' ',line))-1) [first field number]
,substring(line
,(charindex('goes before field',line) + len('goes before field') +1)
,((charindex(' ',line,(charindex('goes before field',line) + len('goes before field') +1)))
-
(charindex('goes before field',line) + len('goes before field') +1))) [second field number]
,substring(line, charindex(' for ',line)+5,99) [full name]
from dbo.char_data_lines
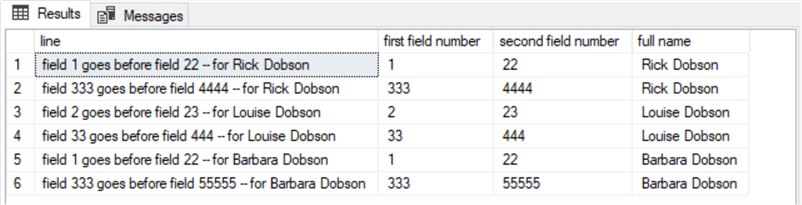
where not(left(line, 15) = 'this is the end' or left(line, 18) = 'this marks the end')구문 분석 코드의 역할과 작동에 대해 학습하는 좋은 방법은 대량 삽입 문 뒤에 있는 select 문에서 설정된 결과를 보는 것입니다. 다음은 앞의 스크립트를 실행한 후 SQL Server 관리 스튜디오의 결과 탭에서 발췌한 것입니다.
- 스크립트에서 설정한 결과 집합에는 6개의 행만 있습니다. 이러한 행은 대량 삽입 문 내의 FROM 절에서 참조하는 TXT 파일의 각 사람에 대한 두 줄에 해당합니다. char_data_lines 테이블 행의 행 값 변환은 네 가지 SQL Server 문자열 함수(substring, charindex, len, left)를 사용하여 구현됩니다.
- select 문 끝에 있는 where 절은 대량 삽입 문에서 참조하는 각 개인 및 전체 소스 파일의 데이터 끝을 표시하는 줄을 제외합니다.
- 각 줄에서 세 개의 필드가 추출됩니다:
- 한 줄에서 단어 필드의 첫 번째 인스턴스 뒤에 오는 번호입니다.
- 한 줄에서 단어 필드의 두 번째 인스턴스 뒤에 오는 번호입니다.
- 각 사람에 대해 두 줄 각각에 해당 사람의 성명을 입력합니다.
사용 사례 #2: 세 개의 CSV 파일을 SQL Server 테이블로 가져오기 및 분류하기
두 번째 사례 연구 예제는 대량 삽입 문이 포함된 세 개의 CSV 파일을 SQL Server 테이블로 가져옵니다. 세 파일 모두 콘텐츠의 레이아웃이 동일합니다. 파일 행은 주식 시세와 날짜별로 고유합니다. 각 행의 열에는 하루 동안 거래된 주식 수뿐만 아니라 다양한 종류의 가격이 포함됩니다. 이러한 일반적인 데이터 레이아웃은 여러 지점의 영업사원이 받은 급여, 커미션, 보너스를 추적하거나 웹사이트의 여러 페이지를 통해 입력된 주문의 수와 금액을 추적하는 등 많은 비즈니스 애플리케이션에서 흔히 볼 수 있는 방식입니다.
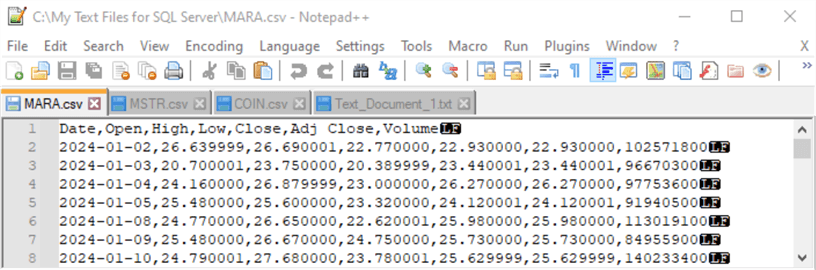
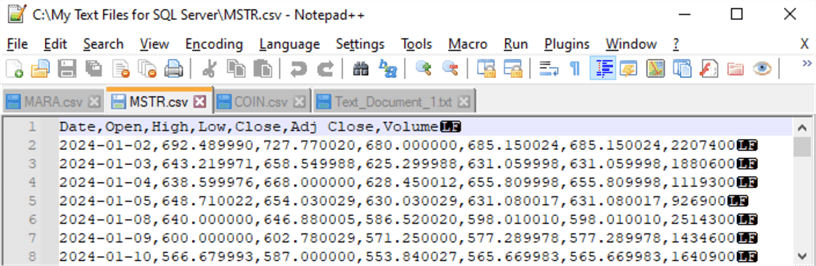
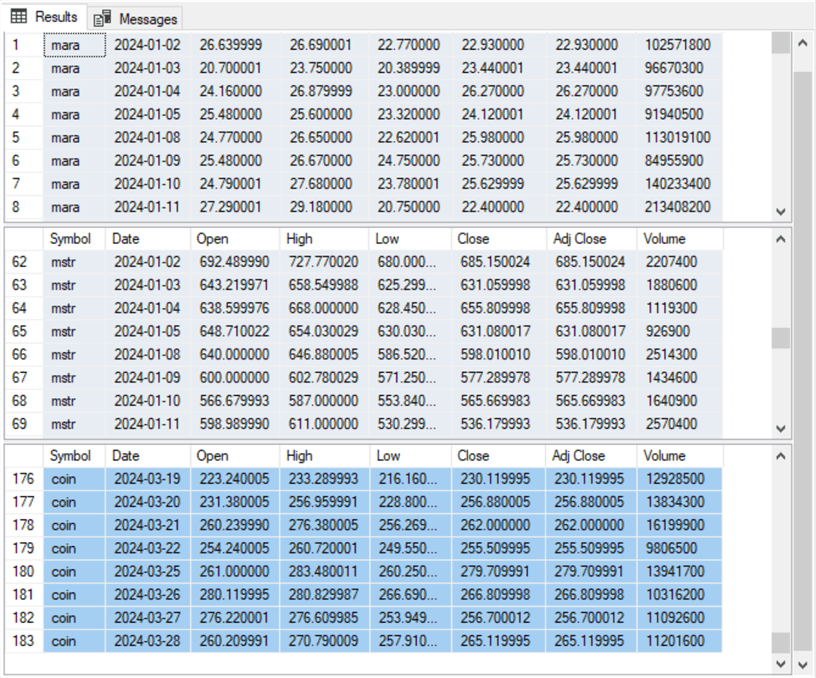
다음 표는 세 파일 각각에서 발췌한 내용입니다. 파일 이름은 MARA.csv, MSTR.csv, COIN.csv입니다. 이 파일들은 앞의 사용 사례 예와 동일한 Windows 드라이브 및 폴더(C:\My Text Files for SQL Server)에 있습니다.
- 맨 위 테이블 셀에는 MARA.csv의 처음 8개의 행이 표시됩니다. 이 발췌문에는 열 머리글(날짜, ..., 볼륨)과 날짜 및 숫자 값이 표시됩니다.
- 가운데 테이블 셀에는 MSTR.csv의 처음 8개의 행이 표시됩니다. 보시다시피 데이터의 레이아웃은 MARA.csv 파일과 동일합니다. 또한 날짜 값은 상단 및 중간 테이블 셀에서 동일합니다(2024-01-02에서 시작하여 2024-01-10에서 끝남).
- 아래쪽 테이블 셀에는 COIN.csv의 마지막 8개 행이 표시됩니다. 이 테이블 셀의 데이터 레이아웃은 열 머리글이 표시되지 않는다는 점을 제외하면 앞의 두 테이블 셀과 일치합니다. 열 머리글은 선택적으로 CSV 파일에 포함될 수 있습니다. 이 사용 사례 예제에서는 세 개의 CSV 파일 모두 첫 번째 파일 행에 열 머리글이 있습니다. 또한 세 CSV 파일 모두 동일한 종료 날짜(2024-03-28)를 가지며, 이는 하단 테이블 셀의 맨 아래 행에 첫 번째 필드 값으로 나타납니다.
다음 스크립트는 세 개의 CSV 파일을 SQL Server 테이블로 가져오기 위한 T-SQL 코드를 보여줍니다. 스크립트에는 한 줄 주석 마커 행으로 서로 구분되는 네 개의 세그먼트가 있습니다.
- 첫 번째 세그먼트는 스크립트의 기본 데이터베이스로 for_char_data_lines 데이터베이스를 지정하는 것으로 시작됩니다. 이 세그먼트는 또한 두 테이블의 새 버전을 생성합니다.
- SQL Server 테이블 1: 세 CSV 파일 각각에 대한 원본 내용을 dbo.imported_data_for_a_category 테이블에 저장합니다. 이 테이블은 세 개의 CSV 파일 각각에 대해 새로 채워집니다. 이 테이블의 열은 이전 테이블에 표시되는 테이블 발췌에 해당합니다.
- SQL Server 테이블 2(dbo.imported_data_across_categories): 세 CSV 파일 모두의 데이터를 저장합니다. 테이블의 첫 번째 열에는 이름 기호가 있습니다. 이 열에는 각 CSV 파일의 티커 기호가 저장됩니다. 즉, 기호 열은 각 CSV 파일의 행을 분류합니다.
- 두 번째 세그먼트는 세 단계로 구성됩니다.
- 1단계: 4개의 매개변수 설정에 의존하는 대량 삽입 문을 사용하여 MARA.csv 파일의 내용을 dbo.imported_data_for_a_category 테이블에 복사합니다:
- 형식은 가져오는 문자 데이터의 유형, 즉 CSV 파일의 문자 데이터에 대한 형식입니다,
- 첫 번째 행은 소스 파일의 시작 데이터 행을 지정합니다,
- 필드 종결자는 필드 값의 구분 문자(,)를 지정합니다,
- 행종결자는 행의 끝을 표시하는 문자(0x0a)를 지정하며, 일반적으로 사용되는 또 다른 행종결자 값은 (\n\r)입니다.
- 2단계: dbo.imported_data_for_a_category 테이블의 내용을 dbo.imported_data_across_categories 테이블에 복사(대량 삽입 문 사용)합니다. 또한 이 단계에서는 세그먼트의 소스 CSV 파일 이름인 mara로 dbo.imported_data_across_categories 테이블의 기호 열을 채웁니다.
- 3단계: SQL Server Management Studio의 결과 탭에 dbo.imported_data_across_categories 테이블의 내용을 에코합니다.
- 1단계: 4개의 매개변수 설정에 의존하는 대량 삽입 문을 사용하여 MARA.csv 파일의 내용을 dbo.imported_data_for_a_category 테이블에 복사합니다:
- 몇 가지 예외를 제외하고 세 번째 및 네 번째 세그먼트는 두 번째 세그먼트와 동일합니다.
- 이 두 세그먼트는 모두 dbo.imported_data_for_a_category 테이블에 대한 truncate table 문으로 시작됩니다. 테이블을 잘라내는 문은 대량 삽입 문을 실행하여 다른 CSV 파일에서 새 데이터를 복사하기 전에 테이블에서 이전 데이터를 모두 지우는 데 필요합니다. 두 번째 세그먼트는 dbo.imported_data_for_a_category 테이블이 이전에 채워지지 않았기 때문에 truncate table 문이 필요하지 않습니다.
- 세 번째 및 네 번째 세그먼트는 두 번째 세그먼트와 다른 값(mara)으로 dbo.imported_data_across_categories 테이블의 기호 열을 채웁니다.
- 세 번째 세그먼트에서 기호 열에 할당된 문자열 값은 mstr입니다.
- 네 번째 세그먼트에서 기호 열에 할당된 문자열 값은 코인입니다.
use for_char_data_lines;
-- create fresh versions of the
-- dbo.imported_data_for_a_category and -- the dbo.imported_data_across_categories tables
drop table if exists dbo.imported_data_for_a_category;
create table dbo.imported_data_for_a_category (
[Date] date
,[Open] dec(21,6)
,[High] dec(21,6)
,[Low] dec(21,6)
,[Close] dec(21,6)
,[Adj Close] dec(21,6)
,[Volume] dec(19,0)
);
drop table if exists dbo.imported_data_across_categories;
create table dbo.imported_data_across_categories (
[Symbol] nvarchar(10)
,[Date] date
,[Open] dec(21,6)
,[High] dec(21,6)
,[Low] dec(21,6)
,[Close] dec(21,6)
,[Adj Close] dec(21,6)
,[Volume] dec(19,0)
);
----------------------------------------------------------
-- bulk insert file to imported_data_for_a_category
bulk insert dbo.imported_data_for_a_category
from 'C:\My Text Files for SQL Server\MARA.csv'
with (
format = 'CSV'
,firstrow = 2
,fieldterminator = ','
,rowterminator = '0x0a')
-- optionally display dbo.imported_data_for_a_category
-- select * from dbo.imported_data_for_a_category
-- insert imported_data_for_a_category -- into dbo.imported_data_across_categories
-- with category id as symbol column value
insert into dbo.imported_data_across_categories
select 'mara', * from dbo.imported_data_for_a_category
-- optionally display dbo.imported_data_across_categories
select * from dbo.imported_data_across_categories
----------------------------------------------------------
-- erase contents of dbo.imported_data_for_a_category;
truncate table dbo.imported_data_for_a_category;
-- bulk insert file to imported_data_for_a_category
bulk insert dbo.imported_data_for_a_category
from 'C:\My Text Files for SQL Server\MSTR.csv'
with (
format = 'CSV'
,firstrow = 2
,fieldterminator = ','
,rowterminator = '0x0a')
-- optionally display dbo.imported_data_for_a_category
-- select * from dbo.imported_data_for_a_category
-- insert imported_data_for_a_category -- into dbo.imported_data_across_categories
-- with category id as symbol column value
insert into dbo.imported_data_across_categories
select 'mstr', * from dbo.imported_data_for_a_category
-- optionally display dbo.imported_data_across_categories
select * from dbo.imported_data_across_categories
----------------------------------------------------------
-- erase contents of dbo.imported_data_for_a_category;
truncate table dbo.imported_data_for_a_category;
-- bulk insert file to imported_data_for_a_category
bulk insert dbo.imported_data_for_a_category
from 'C:\My Text Files for SQL Server\COIN.csv'
with (
format = 'CSV'
,firstrow = 2
,fieldterminator = ','
,rowterminator = '0x0a')
-- optionally display dbo.imported_data_for_a_category
-- select * from dbo.imported_data_for_a_category
-- insert imported_data_for_a_category -- into dbo.imported_data_across_categories
-- with category id as symbol column value
insert into dbo.imported_data_across_categories
select 'coin', * from dbo.imported_data_for_a_category
-- optionally display dbo.imported_data_across_categories
select * from dbo.imported_data_across_categories
----------------------------------------------------------다음 스크린샷은 이전 스크립트의 두 번째, 세 번째, 네 번째 세그먼트 끝에 있는 마지막 선택 문에서 각각 발췌한 세 가지를 보여줍니다.
- 상단 발췌: 마라 기호에 대한 처음 8개의 데이터 행입니다.
- 중간 발췌: mstr 기호에 대한 처음 8개의 데이터 행입니다.
- 하단 발췌: 코인 심볼의 아래쪽 8개의 데이터 행입니다.
사용 사례 #3: 동적 SQL과 저장 프로시저를 사용하여 CSV 파일 가져오기
이전 섹션의 스크립트에서는 대량 삽입 문을 사용하여 여러 CSV 파일을 SQL Server 테이블로 가져오는 방법을 설명합니다. 안타깝게도 대량 삽입 문에는 가져올 각 소스 파일에 대한 리터럴 값이 필요합니다. 가져올 파일이 몇 개만 있는 경우에는 파일 이름 몇 개를 업데이트하는 것이 큰 문제가 되지 않습니다. 그러나 가져올 새 파일의 수가 많아지면 이러한 수동 업데이트로 인해 파일 가져오기 스크립트에 오류가 발생할 수 있습니다.
이 섹션에서는 저장 프로시저에 포함된 동적 SQL과 관련된 이 문제를 해결하기 위한 새로운 스크립트에 대해 설명합니다. 저장 프로시저는 가져올 파일의 이름이 포함된 입력 매개변수를 받아들입니다. 저장 프로시저 내부의 T-SQL은 대량 삽입 문을 호출하는 SQL의 일부를 대체하고 소스 파일의 값으로 대상 테이블을 채웁니다. 따라서 각 소스 파일 이름에 대해 저장 프로시저의 입력 매개변수를 지정하여 이 섹션의 솔루션을 쉽게 실행할 수 있습니다.
스크립트에는 한 줄 댓글 마커 행으로 구분되는 세 개의 세그먼트가 있습니다.
- 첫 번째 세그먼트는 하나의 CSV 파일을 받아들이는 테이블과 가져온 내용을 저장하는 테이블, 각 CSV 파일 이름에 대해 새 열이 있는 두 개의 테이블을 만듭니다.
- 두 번째 세그먼트는 SQL 문자열로 지정된 대량 삽입 문이 포함된 저장 프로시저를 만듭니다. 이 세그먼트는 가져올 파일 이름으로 SQL 문자열을 업데이트한 다음 파일 내용을 받아들이기 위한 첫 번째 테이블을 채웁니다. 다음으로, 저장 프로시저 코드는 파일 이름이 포함된 두 번째 테이블을 가져온 콘텐츠로 채웁니다. 저장 프로시저의 마지막 작업은 첫 번째 테이블을 잘라내어 새 CSV 파일 이름으로 저장 프로시저를 다시 실행할 때 빈 테이블을 사용할 수 있도록 합니다.
- 세 번째 세그먼트는 두 번째 세그먼트에서 생성된 스크립트를 실행하여 첫 번째 세그먼트에서 생성된 두 파일을 채우는 방법을 보여줍니다. 세 번째 세그먼트에는 네 줄의 코드만 있습니다.
- 라인 1-3: 세 개의 CSV 파일 이름 각각에 대해 저장 프로시저를 호출합니다.
- 4줄: 다음 코드 샘플에서 두 번째 테이블의 내용을 모든 소스 파일(MARA.csv, MSTR.csv 및 COIN.csv)의 값과 함께 표시합니다.
다음은 위에서 설명한 스크립트입니다. 첫 번째와 두 번째 세그먼트는 한 번만 작동합니다. 각 세그먼트가 한 번 실행된 후에는 가져와야 하는 파일 수만큼 저장 프로시저를 다시 실행할 수 있습니다. SQL Server로 가져온 각 파일은 C 드라이브의 SQL Server용 내 텍스트 파일 폴더에 있어야 합니다.
use for_char_data_lines;
-- create fresh versions of the
-- dbo.imported_data_for_a_category
-- and dbo.imported_data_across_categories
drop table if exists dbo.imported_data_for_a_category;
create table dbo.imported_data_for_a_category (
[Date] date
,[Open] dec(21,6)
,[High] dec(21,6)
,[Low] dec(21,6)
,[Close] dec(21,6)
,[Adj Close] dec(21,6)
,[Volume] dec(19,0)
);
drop table if exists dbo.imported_data_across_categories;
create table dbo.imported_data_across_categories (
[Symbol] nvarchar(10)
,[Date] date
,[Open] dec(21,6)
,[High] dec(21,6)
,[Low] dec(21,6)
,[Close] dec(21,6)
,[Adj Close] dec(21,6)
,[Volume] dec(19,0)
);
----------------------------------------------------------
-- create stored proc to populate @filename and
-- dbo.imported_data_for_a_category
-- populate dbo.imported_data_across_categories
-- based on @filename and dbo.imported_data_for_a_category
drop procedure if exists dbo.add_rows_to_table_from_a_file;
go
-- add code to start stored proc here
create procedure dbo.add_rows_to_table_from_a_file
(@infilename nvarchar(10))
as
begin
declare
@sql nvarchar(max)
,@sql_b4replace nvarchar(max)
,@path nvarchar (100)
,@filename nvarchar(10)
-- assign @infilename parameter value
-- to @filename local variable
set @filename = @infilename
-- dynamic sql base code for the stored procedure
set @sql_b4replace = '
bulk insert dbo.imported_data_for_a_category
from ''C:\My Text Files for SQL Server\csv_file_name.csv''
with (
format = ''CSV''
,firstrow = 2
,fieldterminator = '',''
,rowterminator = ''0x0a'')
'
-- invoke replace function for @sql_b4replace
-- to set @sql for a new source file
set @sql = replace(@sql_b4replace,'csv_file_name',@filename)
-- execute @sql for current value of @filename
exec (@sql)
-- insert imported_data_for_a_category -- into dbo.imported_data_across_categories
-- with category id as symbol column value
insert into dbo.imported_data_across_categories
select @filename, * from dbo.imported_data_for_a_category
-- truncate dbo.imported_data_for_a_category
-- for the next category if there is one
truncate table dbo.imported_data_for_a_category
end
go
----------------------------------------------------------
-- successively invoke the stored procedure -- for each filename
exec dbo.add_rows_to_table_from_a_file 'mara';
exec dbo.add_rows_to_table_from_a_file 'mstr';
exec dbo.add_rows_to_table_from_a_file 'coin';
-- optionally display dbo.imported_data_across_categories
select * from dbo.imported_data_across_categories이 섹션의 코드 실행 지침은 이전 섹션과 동일한 파일에 대한 것이므로 이전 섹션의 마지막에 동일한 결과 탭 출력이 표시됩니다.
'DataBase' 카테고리의 다른 글
| [MSSQL] CHARINDEX 함수 가이드: 문자열 위치 찾기와 활용법 (0) | 2024.11.02 |
|---|---|
| [MSSQL] SUBSTRING 함수 완벽 가이드 - 문자열 추출과 데이터 마스킹 활용법 총정리 (1) | 2024.11.02 |
| MySQL에서 복합 유니크 인덱스: 다수의 인덱스와 하나의 인덱스를 비교하여 최적의 설계 방식 찾기 (0) | 2024.10.28 |
| MySQL 파티셔닝(Partitioning)의 기본 개념과 필요성 (0) | 2024.10.26 |
| MySQL GROUP BY에 대한 이해 (0) | 2024.10.24 |



